
В бизнесе часто требуется работать с большим числом договоров. По сути, каждый договор нужно прочитать и понять, нет ли в нём «подводных камней». Чтение договоров — скрупулёзный и неблагодарный труд, кроме того, требующий юридического и экономического образования хотя бы в минимальном объёме.
Есть жизненные ситуации, когда человек может рисковать довольно большой суммой денег из-за какой-то строчки или формулировки в договоре. Безусловно, все юридически обязывающие договоры я читаю, но почему бы не автоматизировать эту работу?

Как у меня получилось автоматизировать анализ договоров.
Задавшись таким вопросом, я написал программу, которая принимает на вход договор (Word-документ) и добавляет в этот документ примечания на поля с указанием типа риска пункта договора (штрафы, задержки, затраты и т. п.) и кратким пояснением этого риска.
Программу назвал «Catch», от английского What’s the catch? — В чём подвох?
Для автоматизированного анализа договора я использовал нейросеть OpenAI ChatGPT, конкретно модель gpt-4-0613. Адекватная поддержка русского языка для меня является наиболее определяющим фактором, и альтернатив ChatGPT на данный момент нет (сентябрь 2023), по крайней мере, мне они неизвестны. Я также пробовал gpt-3.5-turbo-0613, но качество анализа текстов было хуже.
Суть программы сводится к тому, чтобы сформировать запрос (prompt) к модели и получить от нейросети ответ в формате JSON (номер параграфа, тип риска), а затем вставить примечания в оригинальный документ Word.
В процессе обнаружилось, что для 15-страничного договора находилось более 70 «проблем», что меня не устроило. Если пользователю нужно вчитаться в 70 пунктов, то это никак не упрощает задачу пользователя увидеть самое главное. Поэтому я добавил приоритезацию рисков. Только риски самого высокого приоритета для данного договора попадают в результат. Таким образом, избавились от тривиальных результатов, не несущих ценности для пользователя. Вместо 70 для того же документа получаем всего 7 подвохов, но самых полезных, как на скриншоте выше.
Я проанализировал несколько договоров, и остался довольным результатом: галлюцинации хорошо отфильтровывались, результат был всегда адекватным и полезным.
Анализ 10 страниц договора на русском языке по текущим расценкам ChatGPT API обходится в 60 рублей (60 центов, по курсу ЦБ РФ) и занимает несколько минут.
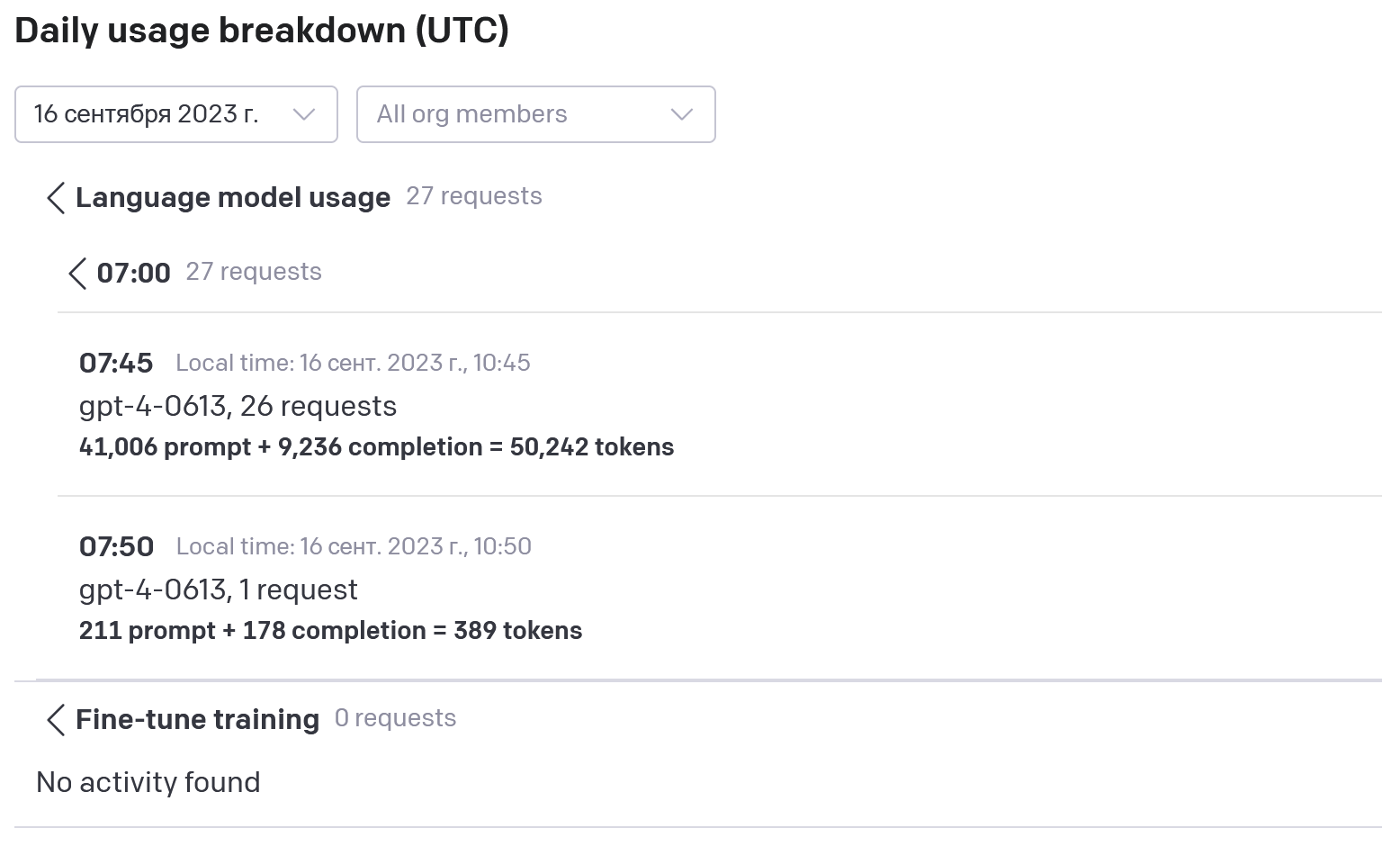
Расход токенов на анализ двух разных договоров примерно по 15 страниц каждый.
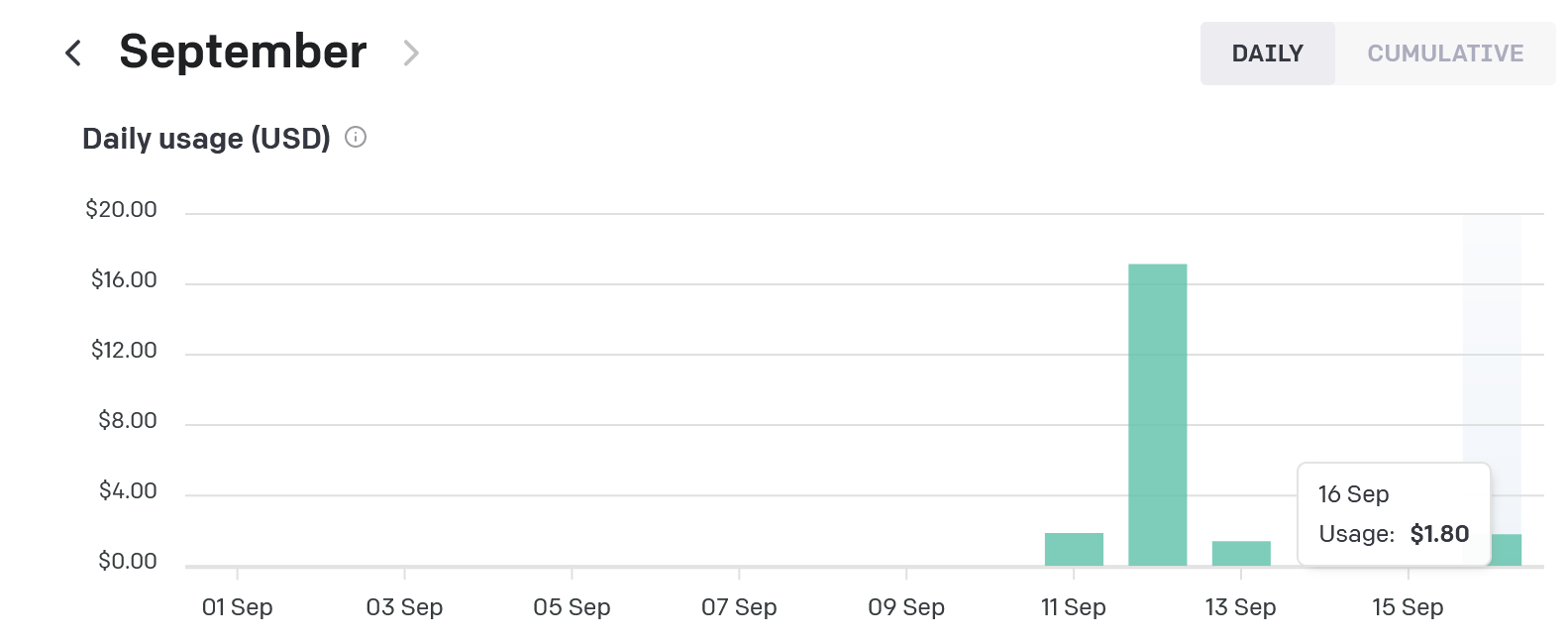
16 сентября затраты $1.80 на анализ двух разных договоров примерно по 15 страниц каждый.
Основной расход токенов на prompt, который, как можно понять, и является текстом договора. Можно ли каким-то образом снизить этот расход токенов? Пишите в комментариях, если знаете.
Такая себестоимость решения, а также длительность обработки запроса нейросетью, является, на мой взгляд, наибольшим барьером для этой технологии.
Если у вас в штате уже есть сотрудник, который имеет достаточные компетенции для анализа договора, и делает это в рамках своих трудовых обязанностей на окладе, то вполне вероятно, что он может это сделать и дешевле и эффективнее, чем программа. Если же у вас нет такого человека (или вы и есть тот самый сотрудник), то для вас это может быть определённой экономией сил, однако, на текущем развитии технологий, это может быть слишком дорого и долго.
Нужно ждать дальнейшего развития технологии, в частности, очень не хватает доступных адекватных русскоязычных нейросетей, из-за чего приходится работать с американской OpenAI, а не с производителями внутри страны. В конечном счёте, это вопрос времени, а сейчас мы уже можем прикоснуться к будущему.

Разные типы рисков подсвечиваются в документе разными цветами.
Начинал я с более смелых гипотез, что можно «на лету» отсканировать текст документа в мобильном приложении с помощью камеры и получить результат.
К сожалению, работающих распознавателей текста на кириллице на устройстве в 2023 году нет. OCR для русского текста требует обязательного подключения к интернету к сервису от Google или ABBYY, но результат этого распознавания также не удовлетворителен, его нельзя без обработки человеком передать в на вход ChatGPT и ожидать приемлемых результатов.
И последнее, что я хочу затронуть в этой статье: вопрос коммерческой тайны. Зачастую условия договоров могут представлять коммерческую или банковскую тайну. Загружать их на любые сервера для анализа может быть неприемлемо. Поэтому в идеале для такой программы необходимо запускать генерирующую модель на компьютере или мобильном устройстве пользователя.
Следовательно, что коммерческий успех в этом направлении возникнет у тех, кто сможет выполнить следующее первым:
- появится возможность запуска моделей на слабых устройствах (хороший прогресс у проекта llama.cpp);
- появятся адекватные модели на русском языке (быстрый и качественный анализ текстов).
Если вам интересен опыт иностранных компаний в этом направлении, то есть решение от docsum.ai. Но оно тоже обладает недостатком, что контракт нужно загружать к ним в облако. Как видим, есть интерес к этой сфере, есть платёжеспособный спрос и есть попытки реализовать решение, поэтому технологии будут развиваться.
Надеюсь, вам было интересно. Пишите в комментариях, если по какому-то вопросу нужно больше информации.